Introduction
类别不均衡(Class Imbalance)是真实场景中非常常见的问题。一般在我们提及类别不均衡时,默认指的是数量不均衡:即不同类中训练样本数量的不一致带来的模型于不同类别学习能力的差异,由此引起的一个严重问题是模型的决策边界会主要由数量多的类来决定 。
但是在图结构中,不同类别的训练样本不仅有在数量上的差异,也有在位置结构上的差异.这就使得图上的类别不均衡问题有了一个独特的来源:拓扑不均衡。这个工作最主要的动机就是研究拓扑不均衡的特点,危害以及解决方法,希望能够引起社区对拓扑不均衡问题的重视。
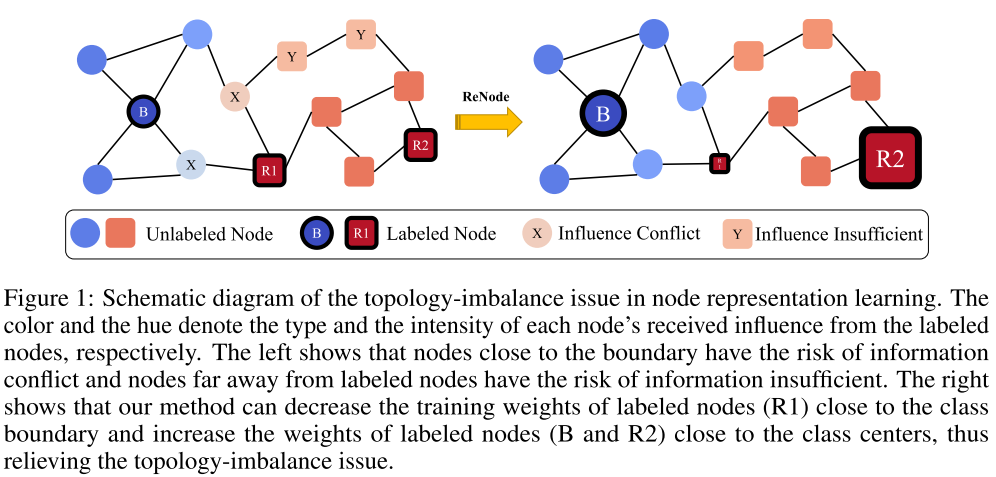
本文提出Topology-Imbalance Node Representation Learning (TINL), 主要关注拓扑不平衡导致的决策边界漂移。所谓拓扑不平衡值得是, labeled nodes的位置如果位于拓扑中的决策边界,那么会传播错误的影响。 如上图所示,颜色和色调分别表示节点从labeled node接收到的influence类型和强度,节点R1位于两类节点的拓扑边界,第一张图可以看出,两个$\mathbf{x}$节点面临influence conflict问题,两个$\mathbf{Y}$节点由于远离R2,面临影响力不足的问题。也就是,如果决策便捷有labeled node(如R1), 那么他的影响力很容易传播给另一个类的边界unlabeled节点,导致影响力冲突,从而分类错误。 而冲突较小的labeled node更可能位于类的拓扑中心(如R2),顾增加其权重,是的它在训练过程中发挥更大作用。
Understanding Topology Imbalance via Label Propagation
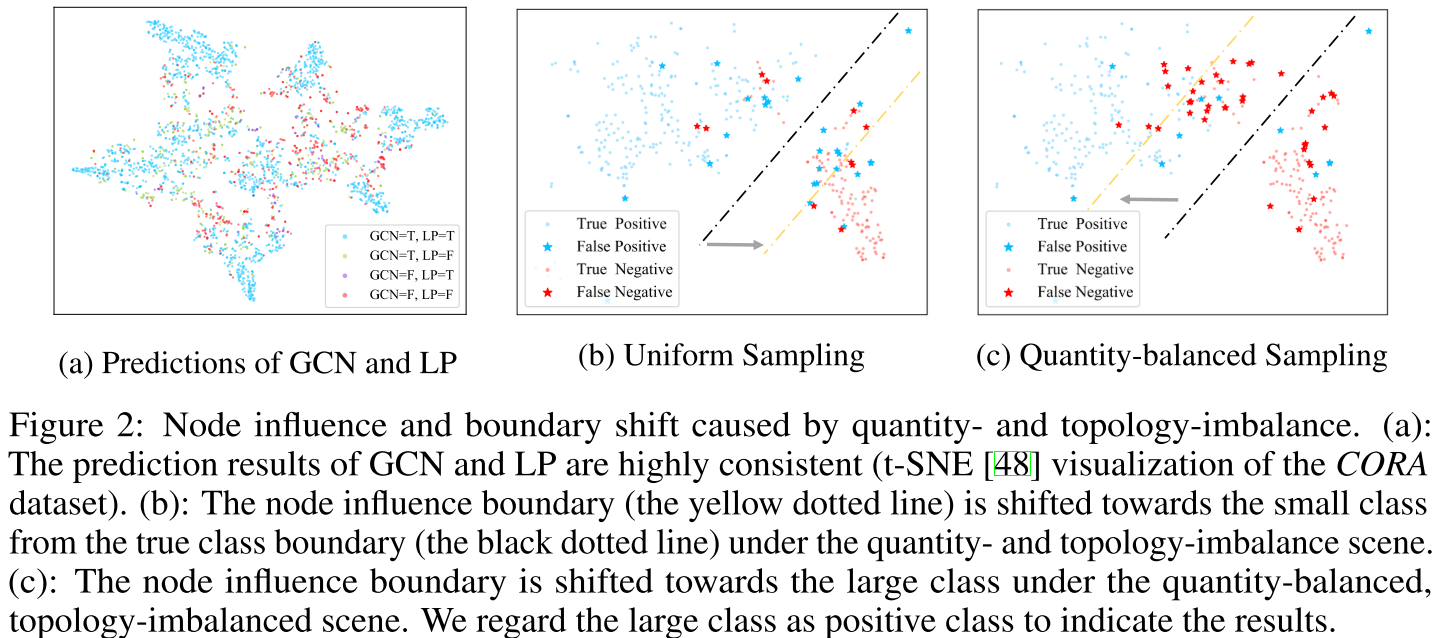
Label Propagation中,labels从labeled node延边传播, 看做label从labeled node开始的随机游走过程。LP最终收敛状态可以认为每个节点的soft-labels: $$ \boldsymbol{Y}=\alpha\left(\boldsymbol{I}-(1-\alpha) \boldsymbol{A}^{\prime}\right)^{-1} \boldsymbol{Y}^{0} $$ 其中$\boldsymbol{A}^{\prime}=\boldsymbol{D}^{-\frac{1}{2}} A D^{-\frac{1}{2}}$,其实就是PageRank的极限分布, $\boldsymbol{Y}^{0}$为每个节点的初始one-hot label。 第$i$个节点的预测结果为$\boldsymbol{q}_{i}=\arg \max _{j} \boldsymbol{Y}_{i j}$,每个节点的预测向量反映了每个节点主要受哪个类的影响。图(a)反映了GCN与LP的预测一致性,所以LP的节点影响力边界可以作为GNN的决策边界。理想状态下,labeled node的影响力边界应与真实类边界一致,例如红色的labeled node 在LP下所传播的影响力范围,应与所有红色node的范围一致。但是如图(b)所示,蓝色的labeled node如果较多位于真实类边界,这些位于边界的节点也会传播影响力,从而导致位于边界的真是红色节点被预测为蓝色,预测边界向红色类偏移。
Measuring Topology Imbalance by Influence Conflict
可以看出,位于决策边界的labeled node 会不可避免的将影响力传播到其他类节点,因此需要衡量labeled node与其所属类的相对拓扑位置(位于类边缘还是中心)。由于Homophily, 位于类边缘的节点也具有和其邻居相似的性质,因此利用邻域特征差别来判断labeled node是否位于边缘是不可靠的。因此本文利用整个图中的节点影响力冲突,提出基于冲突检测的拓扑相对位置Conflict Detection-based Topology Relative Location metric (Totoro).
Personalized PageRank矩阵定义为: $$ \boldsymbol{P} = \alpha\left(\boldsymbol{I}-(1-\alpha) \boldsymbol{A}^{\prime}\right)^{-1} $$ $\boldsymbol{P}_{ij} = \boldsymbol{P}(j \to^\infty i)$, 可以用来反映拓扑中节点$i$对节点$j$的影响力(随机游走越有可能到达的两个节点,在拓扑中的越能相互影响)。
Node influence conflict denotes topological position. $\boldsymbol{P}$可以看做每个节点向外施加影响力的分布。 如果一个labeled node $v$ 在周围子图中受到了来自其他类中的labeled node的异质影响,而$v$本身也具有较大的影响力,那么可以认为$v$具有较大影响力冲突,他更可能位于所在类的拓扑边界。
基于上述假设,本文将 从节点$v$开始在图上随机游走时, 节点$v$与其他类的labeled nodes之间的影响力冲突的期望作为节点$v$与其所在类的类中心的接近程度的度量。labeled node $v$ 的Totoro值定义如下: $$ \boldsymbol{T}_{v}=\mathbb{E}_{x \sim \boldsymbol{P}_{v, :}}\left[\sum_{j \in[1, k], j \neq \boldsymbol{y}_{v}} \frac{1}{\left|\mathcal{C}_{j}\right|} \sum_{i \in \mathcal{C}_{j}} \boldsymbol{P}_{i, x}\right] $$ 其中, $\mathbb{E}_{x \sim \boldsymbol{P}_{v, :}}$: $x$节点受$v$的影响程度,$\sum_{j \in[1, k], j \neq \boldsymbol{y}_{v}}$表示其他所有类(不包括$v$所在的类)。 $\frac{1}{\left|\mathcal{C}_{j}\right|} \sum_{i \in \mathcal{C}_{j}} \boldsymbol{P}_{i, x}$表示类$\mathcal{C}_{j}$中的labeled node对$x$的平均影响。 $\boldsymbol{T}_{v}$越大,表示labeled node $v$对$x$的影响力很大,而且其他类的labeled node 对$x$的影响也很大,那么可以认为$v$越接近类边界。
整个数据集的conflict可以表示为所有labeled node 的Totoro value之和:$\sum_{v \in \mathcal{L}} \boldsymbol{T}_{v}$
Node Re-weighting
Preliminary
余弦退火: $$ \eta_{t}=\eta_{\min }^{i}+\frac{1}{2}\left(\eta_{\max }^{i}-\eta_{\min }^{i}\right)\left(1+\cos \left(\frac{T_{\text {cur }}}{T_{i}} \pi\right)\right) $$ $\eta_{\min }$: 最小学习率
$\eta_{\max }$: 最大学习率
$T_{\text {cur }}$: 当前执行多少个epoch
$i$: 第$i$次迭代

ReNode
本文提出模型无关的训练权重re-weight 机制:ReNode.
本文基于余弦退货算法来为训练节点(labeled nodes)加权: $$ \boldsymbol{w}_{v}=w_{\min }+\frac{1}{2}\left(w_{\max }-w_{\min }\right)\left(1+\cos \left(\frac{\operatorname{Rank}\left(\boldsymbol{T}_{v}\right)}{|\mathcal{L}|} \pi\right)\right), \quad v \in \mathcal{L} $$ 上式中$\boldsymbol{T}_{v}$越大(越接近决策边界),在所有labeled node $v \in \mathcal{L}$的排名越高,$\operatorname{Rank}\left(\boldsymbol{T}_{v}\right)$越大,$\boldsymbol{w}_{v}$越小,越接近$w_{\min }$。
最终,对于一个quantity-balanced,topology-imbalanced (class labeled node 数量是平衡的,但拓扑不平衡) node classification task, the training loss $L_T$ is computed by: $$ L_{T}=-\frac{1}{|\mathcal{L}|} \sum_{v \in \mathcal{L}} \boldsymbol{w}_{v} \sum_{c=1}^{k} \boldsymbol{y}_{v}^{* c} \log \boldsymbol{g}_{v}^{c}, \quad \boldsymbol{g}=\operatorname{softmax}(\mathcal{F}(\boldsymbol{X}, \boldsymbol{A}, \boldsymbol{\theta})) $$ 其中$\mathcal{F}$是任意GNN encoder,$g_i$为GNN对第$i$个节点的output。$\boldsymbol{y}_{v}^{* c} \log \boldsymbol{g}_{v}^{c}$为cross-entropy。 对于每个training labeled node,计算它的CE loss时,用这个节点的权重为loss加权,说明越靠近决策边界的节点,他的损失权重尽可能小,意味着model倾向于把它当做一个unlabeled node,它的损失对于总损失贡献较小。
ReNode to Jointly Handle TINL and QINL
若要同时处理数量不平衡且拓扑不平衡问题, loss定义如下: $$ L_{Q}=-\frac{1}{|\mathcal{L}|} \sum_{v \in \mathcal{L}} \boldsymbol{w}_{v} \frac{|\overline{\mathcal{C}}|}{\left|\mathcal{C}_{j}\right|} \sum_{c=1}^{k} \boldsymbol{y}_{v}^{* c} \log \boldsymbol{g}_{v}^{c} $$ 与$L_T$的不同就是多了对类的加权,若labeled node所在的类 training node较少,那么增加权重。同时,接近拓扑边界的节点权重降低。