Introduction
GFM旨在实现跨领域和任务之间的知识共享来提升图机器学习,但是现有的GFM依赖于手工设计并且fixed的backbone GNN架构,不能根据任务或者领域来自适应调整最优的GNN backbone架构。对于此问题,本文通过发现跨领域和任务的不变“图-架构”关系(invariant graph-architecture relationship)来解决该问题。什么是invariant graph-architecture relationship,就是不管是什么领域,图和架构之间存在一种不变的关系,什么样的图就应该对应于什么样的架构。这会带来3个挑战:
- 如何捕获invariant和variant的pattern,其中invariant pattern指的是可以用来可靠预测图的架构的pattern,variant pattern指的是图中不能用来稳定预测图架构的pattern。换句话说,invariant pattern指的是图中可以决定架构的固有图结构,可以形成与对应GNN架构之间的一一对应的不变关系,而variant pattern指的是一个可变pattern,他可能对应于各种GNN架构,对于这类pattern,GNN架构是不确定的。 Invariant relationship between graph data and corresponding architecture 指的是一个架构适用于的固有图结构,即一个GNN架构对什么样的图结构一定适用。
- 如何为不同的领域和任务调整GFM中的GNN架构。
- 如何减轻架构搜索中的数据支配显现(Data domination)。
AutoGFM的核心思想是训练一个架构映射函数 $\pi: \mathcal{G} \to \mathcal{A}$,用于将图数据映射为特定GNN架构。
Architecture Inconsistency in GFM
当前GFM模型存在一个架构不一致(Architecture Inconsistency)问题,也就是说,不同领域不同任务的最优架构不一致。这边拿GFT这个foundation model为例,它在预训练图上预训练一个GNN模型,然后基于预训练图的embedding来构造一堆词汇表,然后下游任务的图基于这些预训练好的词汇表来作预测。其他GFM模型也都会在预训练阶段预训练好一个GNN模块。这个GNN模块的架构,比如可能是GCN也可能是GAT,是固定的。但这样就存在一个问题,就是下游任务的图不一定适用于这个固定的GNN架构。

Preliminary
Problem Formulation
TAG:所有图用Text-attributed graph $\mathcal{G}=(\mathcal{V}, \mathcal{E}, \mathcal{R})$来统一所有图,其中 $\mathcal{R}=r_1, \ldots, r_{|\mathcal{R}|}$是关系数量。
Node of Interest (NOI) Subgraph:用子图分类任务来统一节点级,边级,图级任务。NOI subgraph $G_h$定义为一个在NOI node周围的子图。用 $S_h(v)=\left\{\mathcal{V}_v^h, \mathcal{E}_v^h, \mathcal{R}_v^h\right\}$表示以节点 $v$为中心的 $h$-hop ego-subgraph。
节点级:NOI node 就是节点 $v$本身,因此 $\mathcal{T} = {v}$,NOI graph 表示为 $G_h(\mathcal{T}) = S_h(v)$。
边级:对于一条边 $(v_i,v_j$),定义 $\mathcal{T} = \{v_i, v_j\}$,该任务的NOI graph为 $G_h\left(\left\{v_i, v_j\right\}\right)=S_h\left(v_i\right) \cup S_h\left(v_j\right)$。
图级:NOI graph是整个图。
所有的任务均可以统一成对NOI graph的分类任务。
Graph Neural Architecture Search (GNAS)
对于一个图数据 $\mathcal{D} = (\mathcal{G}, \mathcal{Y})$,图架构搜索旨在搜索一个从graph 到 label的函数 $F_{\alpha,w}: \mathcal{G} \to \mathcal{Y}$,其中 $\alpha \in \mathcal{A}$是架构参数, $\mathcal{A}$是架构空间。 $w\in \mathcal{W}$是权重。最优架构指的是,在该GNN架构下,模型的最优参数对图预测的loss最小,是一个bi-level optimization problem。如下图所示,上面的式子表示找到最有架构 $\alpha^*$,满足该架构的最优参数可以使模型与 $\mathcal{Y}$的loss最小。

Invariant View of Architecture Customization
The goal is to identify invariant relationships between graph data and the correspond architecture, addressing the issue of architecture inconsistency by tailoring graph neural architecture for each data individually. (不变关系:一个图结构一定对应固定的架构,而不会对应于变化的架构,这样的图结构相对于架构空间称为invariant pattern)。
基于此,本文构建了4个核心变量:输入图 $G$,架构 $A$,invariant pattern $Z_I$,variant pattern $Z_V$。将图到架构的映射分为2个成分:encoder $\theta: G \to Z_I$和 predictor $\psi: Z_I \to A$。分别从图中提取invariant pattern,以及用invariant pattern预测最适用于该图的架构。
Assumption:(1) $Z_I=G \backslash Z_V$, invariant pattern $Z_I$用于可靠预测架构;(2) $Z_V \not \perp A$, $Z_V$虽然不能稳定预测架构,但他并不是与架构相互独立;(3) $A \perp Z_V \mid Z_I$, $\mathrm{A}=\psi\left(\mathrm{Z}_I\right)$,表示给定invariant pattern $Z_I$,架构 $A$的选择不会受到 variant pattern $Z_V$的影响。也就是说如果确定了图中的invariant pattern $Z_I$可以决定该图的架构 $A$,那么其他部分 $Z_V$不应该影响 $Z_I$对架构的选择。
上面三个假设可以写为下式:
$$ \max _{\theta, \psi} I\left(\mathrm{Z}_I, \mathrm{~A}\right)-\lambda I\left(\mathrm{Z}_I, \mathrm{Z}_V\right)-\beta I\left(\mathrm{~A}, \mathrm{Z}_V \mid \mathrm{Z}_I\right) $$
即 学到的invariant pattern $Z_I$要和架构完全相关,并且与variant pattern分离,同时在 $Z_I$可以确定架构的情况下, $Z_V$不能对架构的选择产生影响。AutoGFM就是要实现该目标。
AutoGFM
Disentangled Contrastive Graph Encoder
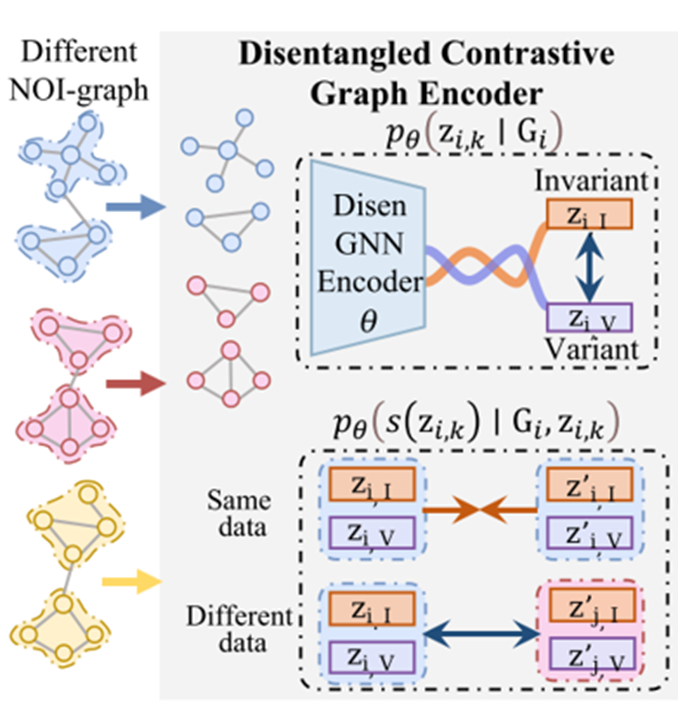
输入是一堆NOI graphs。对于一个NOI graph $G_i$,它的invariant和variant部分需要被disentangle (解纠缠)。Disentangled NOI-graph Encoder用于学习两个channel 的表示:
$$ \begin{aligned}\mathrm{H}_k^{(l)} & =\mathrm{GNN}_k\left(\mathrm{H}_k^{(l-1)}, \mathbf{A}\right), \quad k=1,2, \\ \mathrm{z}_k & =\mathrm{MLP}_k\left(\mathrm{~h}_k\right) \\ \mathrm{h}_k & =\operatorname{Readout}_k\left(\mathrm{H}_k^{(L)}\right), \quad k=1,2 .\end{aligned} $$
这里用两个GNN $\mathrm{GNN}_1$和 $\mathrm{GNN}_2$并行的学习一个图的2个表示 $z_1$和 $z_2$,作为图的invariant表示 $Z_I$和variant表示 $Z_V$。然后,本文提出NOI-graph-level contrastive learning方法来解纠缠的表示可以反应图数据的架构需求。这里要求两个表示被disentangle:
$$ p_\theta\left(\mathrm{z}_{i, k} \mid \mathrm{G}_i\right)=\frac{\exp \phi\left(\mathrm{z}_{i, k}, \mathrm{p}_k\right)}{\sum_{j=1}^2 \exp \phi\left(\mathrm{z}_{i, k}, \mathrm{p}_j\right)} $$
$\mathrm{p}_k$( $k=1,2$)是第 $k$个表示chunk的prototype,用于表示invariant或variant的可学习的protontype,上面的对比函数表示NOI graph $G_i$的表示 $z_{i,1}$要和 $\mathrm{p}_1$相似,$z_{i,2}$要和 $\mathrm{p}_2$相似,而 $z_{i,1}$要和 $\mathrm{p}_2$不相似。以此来区分图中的invariant和variant成分。最大化上面的概率目的是最小化 NOI graph $G_i$ 的 $I\left(\mathrm{Z}_I, \mathrm{Z}_V\right)$。另外,不同NOI graph的invariant representation $Z_I$,需要encourage $Z_I$可以为不同的图数据捕获不同的架构需求,因此对于同一个图的invariant表示 $Z_I$,同一个图的 $Z_I$要相似,不同NOI graph的 $Z_I$要不相似,下面式子用到的 $z$全是 $Z_I$:
$$ p_\theta\left(s\left(\mathrm{z}_{i, k}\right) \mid \mathrm{G}_i, \mathrm{z}_{i, k}\right)=\frac{\exp \phi\left(\mathrm{z}_{i, k}, \mathrm{z}_{i, k}^{\prime}\right)}{\sum_{j=1}^N \exp \phi\left(\mathrm{z}_{i, k}, \mathrm{z}_{j, k}^{\prime}\right)} $$
模型参数 $\theta$的优化目标如下:
$$ \mathcal{L}_{\text {dis }}=\sum_i-\log \mathbb{E}_{p_\theta\left(\mathrm{z}_{i, k} \mid \mathrm{G}_i\right)} p_\theta\left(s\left(\mathrm{z}_{i, k}\right) \mid \mathrm{G}_i, \mathrm{z}_{i, k}\right) $$
旨在区分不同NOI graph的 $Z_I$,使得 $Z_I$可以为不同的图捕获不同的架构需求,同时要让同一个图的invariant和variant表示被区分。
Invariant-guided Architecture Customization
接下来就是要构建不变表示和图架构之间的映射关系。 Invariant representation $Z_I$要可以映射到正确的架构上,对于一个GFM来说,之前的方法是定义一个GNN backbone,这个工作把backbone定义为 $|O|$个候选backbone的组合 $\{GCN, GAT, GIN, \ldots, SAGE\}$,每个GNN都有自己的参数,被联合训练,如下图所示。
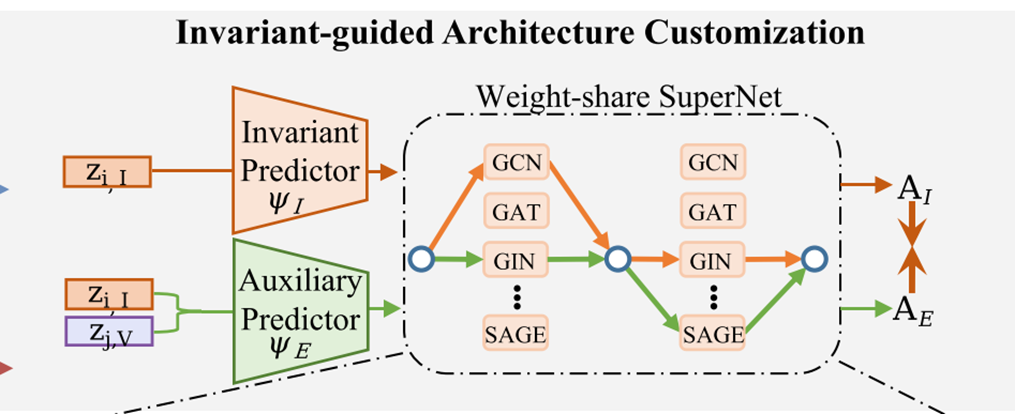
这些GNN组成的超网络表示为:
$$ \mathrm{H}^{(l)} \leftarrow \sum_{i=1}^{|\mathcal{O}|} \alpha_{l, i} \mathrm{GNN}_i^{(l-1)}\left(\mathrm{H}^{(l-1)}, \mathbf{A}\right), $$
也就是当前NOI graph得到的表示是一堆候选GNN的组合。其中 $\alpha_{l, i}$决定了每个GNN操作对给定数据集的贡献。
架构预测器(Architecture Predictor):对于一个图的表示 $z$(不变表示),invariant mapping predictor 定义为 $\psi: z \to \{\alpha_{l,i}\}$。用于将invariant 表示映射为选择每个架构的概率:
$$ \begin{gathered}\hat{\alpha}_{l, i}=\mathrm{z} \cdot \frac{\mathrm{p}_{l, i}}{\left|\left|\mathrm{p}_{l, i}\right|\right|_2} \\ \alpha_{l, i}=\frac{\exp \left(\hat{\alpha}_{l, i}\right)}{\sum_{j=1}^{|\mathcal{O}|} \exp \left(\hat{\alpha}_{l, j}\right)},\end{gathered} $$
其中 $\mathrm{p}_{l, i}$是可学习的prototype,表示第$i$层第$i$个操作的表示,可以看作是architecture representation。若 $\mathrm{H}^{(l)}$可以最好的匹配标签 $\mathcal{Y}$,那么等价于最大化 $I\left(\mathrm{Z}_I, \mathrm{~A}\right)$。
Invariant-guided Customization
上面的优化目标已经可以最大化 $I\left(\mathrm{Z}_I, \mathrm{~A}\right)$以及最小化 $I\left(\mathrm{Z}_I, \mathrm{Z}_V\right)$。最后还有一项,需要在给定 $Z_I$的情况下, $Z_V$不会对架构的选择产生影响,即最小化条件互信息 $I\left(\mathrm{~A}, \mathrm{Z}_V \mid \mathrm{Z}_I\right)$。具体来说,首先用不变pattern $Z_I$,基于架构预测器 $\psi_I$来预测架构 $A_I$。并且用 $Z_I$和 $Z_V$的混合通过辅助预测器 $\psi_E$来预测架构为 $A_E$:
$$ \mathrm{A}_I=\psi_I\left(\mathrm{Z}_I\right), \quad \mathrm{A}_E=\psi_E\left(\mathrm{Z}_I, \mathrm{Z}_V\right) . $$
然后遍历所有图数据,优化目标是使得 所有$A_I$和 $A_E$的差异尽可能小,也就是加上 $Z_V$后,对架构的预测改变要尽可能小:
$$ \begin{aligned}\mathcal{L}_{\mathrm{inv}} & =\sum_i^{||\mathcal{D}||} \sum_j^{||\mathcal{D}||}\left|\left|\mathrm{A}_{I, i}-\mathrm{A}_{E,(i, j)}\right|\right|, \\ \text { s.t. } \quad \mathrm{A}_{I, i} & =\psi_I\left(\mathrm{z}_{I, j}\right), \mathrm{A}_{E, i, j}=\psi_E\left(\mathrm{z}_{I, i}, \mathrm{z}_{V, j}\right),\end{aligned} $$
架构的预测的任务目标是使得最后一层输出 $\mathrm{H}^{(L)}$ 可以做出最好的预测:
$$ \mathcal{L}_{\text {task }}=\ell\left(F_{\psi\left(\mathrm{Z}_I\right)}(\mathrm{G}), \mathrm{y}\right) . $$
AutoGFM的最终loss为:
