1. Harnessing Explanations: LLM-to-LM Interpreter for Enhanced Text-Attributed Graph Representation Learning (TAPE)
Shallow model: Encoding the textual attributes using shallow or hand-crafted features such as skip-gram or bag-of-words (BoW) which used in PgG and DGL are limited in the complexity of the semantic features they can capture.
LM: 指相对较小并且可以被fine-tune的模型。GIANT fine-tune an LM using neighborhood prediction task (在neighborhood prediction task上来微调LM模型). GLEM fine-tune an LM to predict the label distribution from GNN’s output (GLEM 用GNN预测的伪标签作为监督信号,让LM来fine tune 节点的文本表示)。这些工作需要大量的计算资源,并且由于要微调模型的参数,所以选取的LM相对较小,比如BERT和DeBERTa,因此缺乏LLM的推理能力。
LLMs refer to very large language models such as GPT-3/4.
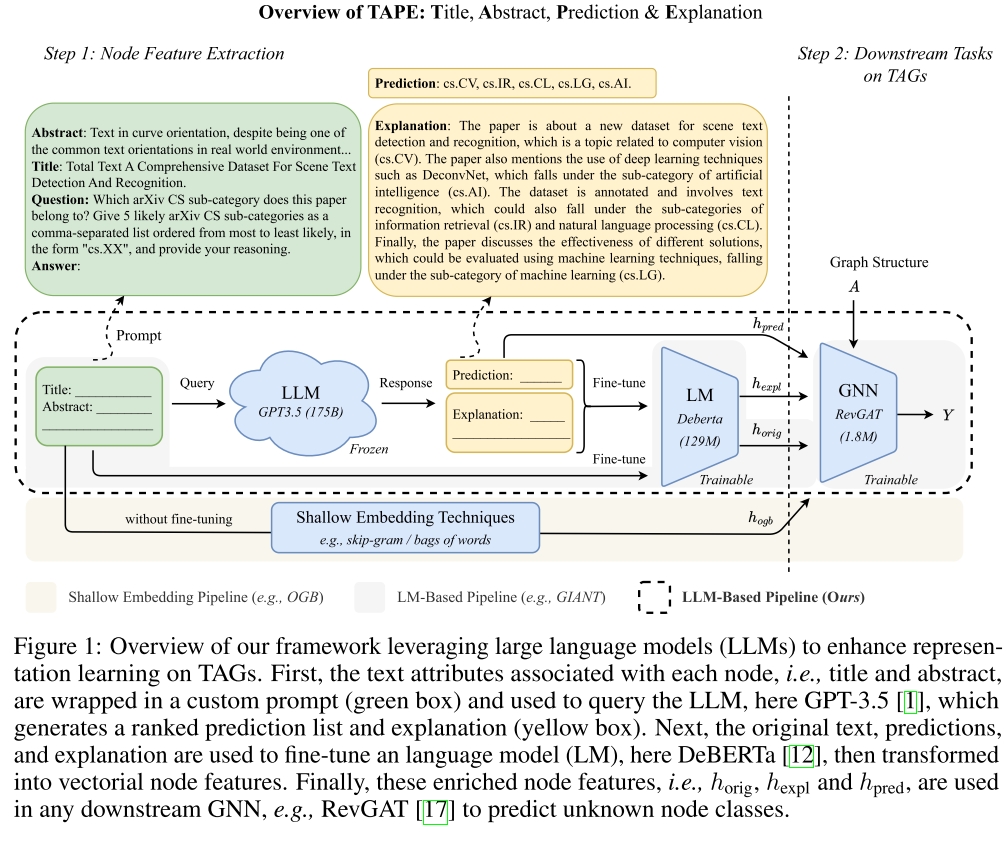
The present work: LLM augmentation using explanations: 使用解释作为node feature。通过LLM来解释它的预测,这些解释传达了text与prediction的相关知识和LLM的推理步骤,这些解释信息更易于小LM模型吸收消化。如上图所示,首先绿框中的节点text属性通过自定义的prompt来询问LLM,比如GPT-3.5,让GPT来生成关于文本类别的预测排名list(黄色框所示),并且提供这些得到这些预测的解释理由。接着,原始text,LLM的预测,以及解释共同用来fine-tune LM,比如BERT或DeBERTa。然后,LM将他们转化为节点的features用于下游预测。
Formalization
LM for text classification $$ h_n=\mathbf{L M}\left(s_n\right) \in \mathbb{R}^d $$ 其中$s_n \in \mathcal{D}^{L_n}$是节点$n$的文本属性。LM是已经被预训练的模型如BERT和DeBERTa。LM可以将文本属性编码为文本的表示向量$h_n$。
LLM and prompting
输入token序列 $x=\left(x_1, x_2, \ldots, x_q\right)$,目标是输出token序列 $y=\left(y_1, y_2, \ldots, y_m\right)$。并且在输入token序列中加入prompt $p$来对输出施加约束。LLM旨在优化一下条件概率: $$ p(y \mid \hat{x})=\prod_{i=1}^m p\left(y_i \mid y_{<i}, \hat{x}\right) $$ 其中$\hat{x}=\left(p, x_1, x_2, \ldots, x_q\right)$是使用prompt约束的input token sequence。
TAPE
使用LLMs生成预测和解释
LLMs的prompt包括文章的title和abstract,并要求LLMs预测paper的一个或多个类别标签,并且将这些类别标签按从高到低的概率排序,并且要求LLMs提供预测的解释理由,完整prompt如下图所示:
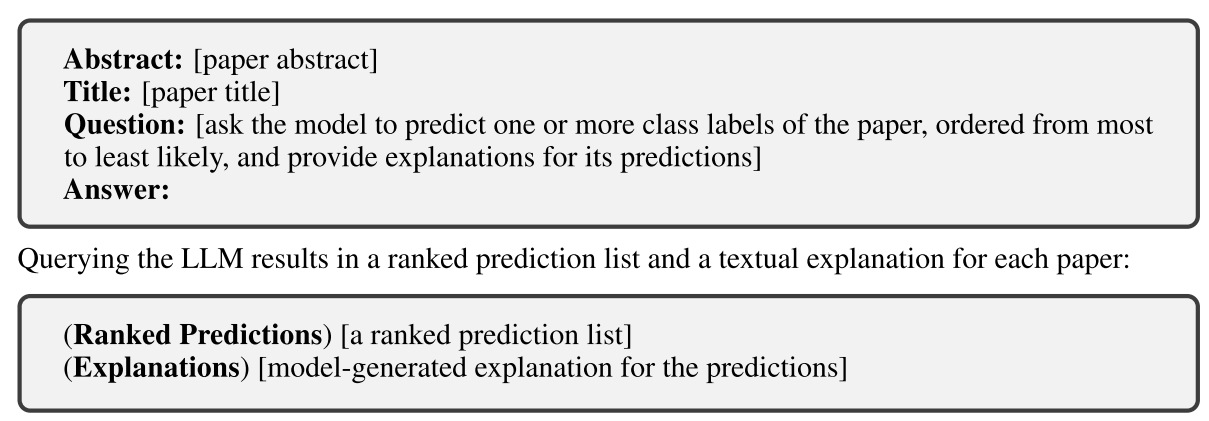
Abstract输入节点对应paper的摘要,Title输入paper的题目,question则要求模型输出一个或多个paper的预测类别标签并按照可能性排序,同时给出预测的解释。
Fine-Tuning LM Interpreter and Node Feature Extraction
将LM作为LLM得到文本解释的“理解器”。给定两个预训练好的LMs $\mathrm{LM}_{\text {orig }}$ 和$\mathrm{LM}_{\text {expl }}$,他们的输入分别是原始文本特征$s^{\text {orig }}$和该文本特征的解释$s^{\text {expl }}$,这样我们可以分别得到原始文本和解释的text embeddings: $$ h_{\text {orig }}=\mathrm{LM}_{\text {orig }}\left(s^{\text {orig }}\right) \in \mathbb{R}^{N \times d}, \quad h_{\text {expl }}=\mathrm{LM}_{\text {expl }}\left(s^{\text {expl }}\right) \in \mathbb{R}^{N \times d} $$ 然后要对LM进行Fine-tuning使其与下游任务。首先使用MLP将原始文本和解释的text embedding分别映射到标签空间: $$ y_{\text {orig }}=\operatorname{MLP}_{\text {orig }}\left(h_{\text {orig }}\right) \in \mathbb{R}^{N \times C}, \quad y_{\text {expl }}=\operatorname{MLP}_{\text {expl }}\left(h_{\text {expl }}\right) \in \mathbb{R}^{N \times C} $$ 通过最小化分类的cross-entropy loss来对LM进行fine-tuning,从而使$\mathrm{LM}_{\text {orig }}$ 和$\mathrm{LM}_{\text {expl }}$可以分别学习到文本和解释与标签之间的关联(什么样的原始文本对应于什么样的标签、什么样的解释对应于什么样的标签)。
Ranked prediction features LLM同时也给出了对于每个节点文本的类别可能性排名,同样也是有价值的信息。假设每个节点有$C=5$个可能的类别数,对这些类别分别做one-hot编码,节点$i$排名第1的类别为类别4,那么$p_{i,1} = [0,0,0,1,0]$,那么LLM为节点$i$预测的top-$k$个label可以拼接成一个$kC$维的向量。然后通过一个线性变换: $$ h_{\text{pred}} = \operatorname{MLP}_{\text {pred }}(\operatorname{Concat}(p_{i,1}, \cdots, p_{i,k})) \in \mathbb{R}^{N\times d_P} $$ 可以得到每个节点的排序预测特征,如Figure 1中的$h_{\text{pred}}$所示。
TAPE node feature: $\{[h_{\text {orig }}, h_{\text {expl }}, h_{\text{pred}}]\}$。其中$h_{\text {orig }}$和$h_{\text {expl }}$是通过LM 对下游任务标签做fine-tuning后的文本特征和解释特征,用来简历原始文本和解释与label之间的联系,$h_{\text{pred}}$是LLMs预测类别标签编码。
GNN Training with TAPE features
对于TAPE的三种特征:LM fine-tuning的原始text embedding $h_{\text {orig }}$, LM fine-tuning的解释text embedding $h_{\text {expl }}$,以及LLM的prediction embedding $h_{\text{pred}}$,使用3个GNN模型分别预测labels: $$ \begin{aligned} \hat{y}_{\text{orig}} &= \operatorname{GNN}_{\text{orig}}(h_{\text {orig }}, A) \in \mathbb{R}^{N \times C}, \\ \hat{y}_{\text{expl}} &= \operatorname{GNN}_{\text{expl}}(h_{\text {expl }}, A) \in \mathbb{R}^{N \times C}, \\ \hat{y}_{\text{pred}} &= \operatorname{GNN}_{\text{pred}}(h_{\text {pred }}, A) \in \mathbb{R}^{N \times C} \end{aligned} $$
然后基于不同特征得到的预测取平均可以得到模型最终的预测label: $$ \hat{y}=\operatorname{mean}\left(\hat{y}_{\text {orig }}, \hat{y}_{\text {expl }}, \hat{y}_{\text {pred }}\right) \in \mathbb{R}^{N \times C} $$
2. Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs
Q1: 能否利用LLMs来弥补图神经网络对contextualized knowledge和semantic comprehension理解不足的缺陷?
Q2: LLM能否独立运行于图结构任务?
LLMs
Embedding-visible LLMs
可以获得words, sentences, documents的具体representations(embeddings),如BERT, Sentence-BERT和Deberta。
Embedding-invisible LLMs
用户无法获取和操作embeddings,通常部署在web服务上,如ChatGPT,只能通过text来进行交互
Detailed four types of LLMs
Pre-trained Languagge Models (PLMs): 指相对较小的LLMs,比如Bert和Deberta,并且可以根据下游数据集进行fine-tuning,比如在下游数据集上fine-tune Deberta然后取最后一个hidden state的embeddings作为text embedding。
Deep Sentence Embedding Models: 使用PLMs作为base encoders,并且将训练好的PLMs进一步进行监督或对比学习预训练。这样的模型通常不需要Fine-tuning。
Large Language Models: 与PLM相比,LLMs具有更强的能力和更多数量级的参数。
LLMs-as-Enhancers
利用LLMs来增强节点的文本属性特征,然后用GNN生成预测。
How LLMs can enhance GNNs by leveraging their extensive knowledge and semantic comprehension capability?
Challenge: 不同的LLMs能力不同,越强大的模型有更多使用限制,因此需要对不同的LLMs针对性设计使用策略来充分利用他们的能力。
Feature-level Enhancement
1. Cascading Structure 级联结构
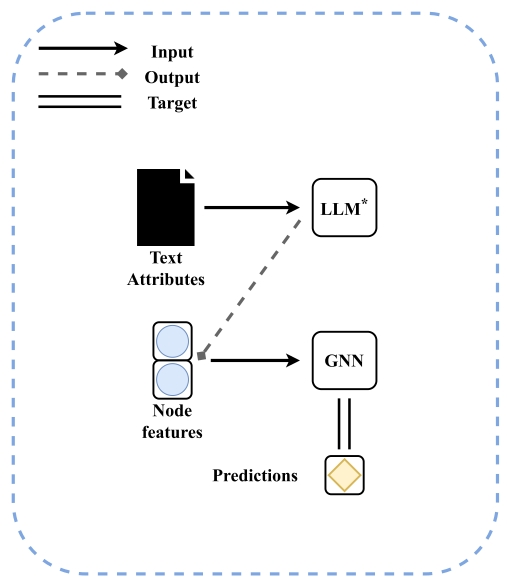
先试用embedding-visible的LLMs来对dataset中的text attribute做fine-tuning,然后生成每个节点的文本特征的embeddings,然后将这些embeddings作为node features,与图结构一起数据GNN中来训练GNN模型。
2. Iterative Structure 迭代结构
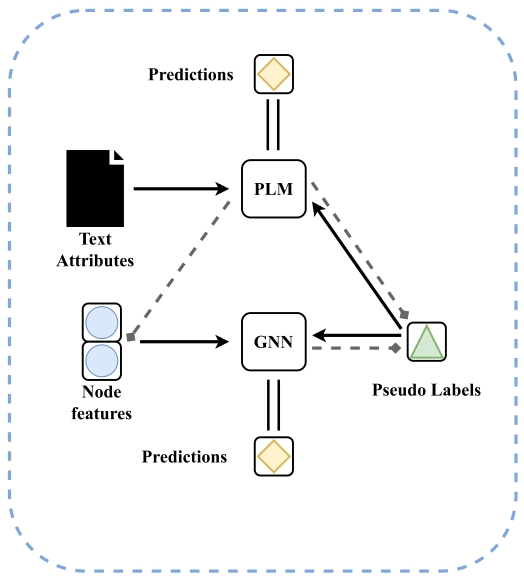
如GLEM[1],在E步根据真实标签和GNN预测的伪标签来训练PLM,在M步根据真实标签和PLM预测的伪标签和PLM学到的text embedding作为node feature来训练GNN模型,然后训练好的GNN模型和PLM模型都可以用来作为节点标签预测器。
Node Classification Comparison
实验结果来看,
- 在下游数据集上fine-tuned PLM模型取最后一层作为text embedding,然后GNN作为predictor的效果来看,fine-tuned PLM并不比简单点TF-IDF强。对于不同的text embedding方式(Fine-tuned PLM,PLM without fine-tuning,online sentence embedding)GNN的表现各不相同。
- 在监督训练数据较少的情况下,fine-tuned PLM和迭代结构的GLEM学习到的text embedding用到GNN后,得到的结果比普通的TF-IDF差。
- 使用Deep Sentence Embedding Models 如sentence-bert学习到的text embedding + GNN predictor的效果较好。
- LLama的效果弱于deep sentence embedding models,说明简单的增加参数并不能生成对GNN有用的text embedding。
Text-level Enhancement
1. TAPE
使用文本和LLM解释来fine-tuning PLM,LLM的分类解释和分类排序作为增强text embedding。
2. Knowledge-Enhanced Augmentation (KEA)
使用额外的knowledge来增强PLM。
Node Classification Comparison
实验结果来看,
- TAPE的效果主要受益于LLMs生成的文本解释。
- TAPE原文中采用PLM (Deberta)作为LM,将text attribute和explanation以及任务的label用来fine-tune PLM。而local sentence embedding model e5-large不fine-tune 直接用text attribute以及LLM的explanation来输出embeddings,相比于TAPE中使用的fine-tuned PLM,e5得到了更好的效果。
LLMs-as-Predictors
LLMs作为独立的predictor
How LLMs can be adapted to explicit graph structures as a predictor?
Challenge: 如何设计prompt使得LLM可以处理图中的structure和attribute信息。
直接使用LLM来预测节点类别标签可以使用以下几种prompt策略:
- Zero-shot prompts: 给定单一节点的文本信息,让LLM预测它的类别标签,如下面的prompt所示。

其中,Paper是一个节点的text attribute,Task提供可能的类别标签,然后prompt要求LLM输出一个最可能的类别。
- Few-shot prompts: 如下图所示,先按照zero-shot的形式给出一些node samples的 prompts,以及这些samples的ground-truth标签。最后,给出目标节点的prompt,要求LLMs输出节点的类别。

- Zero-shot prompts with CoT (Chain-of-Thoughts): 基于zero-shot prompt,在prompt中进一步要求LLM生成思考过程,也就是Think it step by step and output the reason in one sentence (用一句话来概括推理步骤)。

- Few-shot prompts with CoT: 使用第三个prompt的zero-shot prompts with CoT来分别为多个sample生成推理步骤的sentences,然后将这些这些samples的文本内容、Ground-truth标签和CoT process共同作为prompt,并且要求LLM为当前的目标node输出预测标签以及CoT。

3. One for All: Towards Training One Graph Model for All Classification Tasks
What is in-context learning?[2]
“In-Context Learning is a way to use LLMs to learn tasks given only a few examples. During in-context learning, we give the LM a prompt that consists of a list of input-output pairs that demonstrate how to perform a task. At the end of the prompt, we append a test input and allow the LM to make a prediction just by conditioning on the prompt and predicting the next tokens. For example, to answer the two prompts below, the model needs to examine the training examples to figure out the input distribution (financial or general news), output distribution (Positive/Negative or topic), input-output mapping (sentiment or topic classification), and the formatting. "

如上图(from [2])所示,在prompt中包含一些上下文input-output pairs来演示(demonstrate)如何执行任务。在这些prompt的最后添加text input token来让LLM学习上下文中的演示来执行text input token的任务。
Challenge
Foundation Model指用单一模型来解决多个任务。但是Graph Foundation Model面临以下挑战:(1)不同来源的图数据在feature表征上通常完全不同。比如molecular graph中的节点特征是其中原子nominal feature的索引,e-commerce networks中的节点特征通常用Bag-of-Word来编码。这些不同来源的图数据特征维度、语义信息和尺度的差别都很大,几乎不可能用同一个模型来学习他们的表示。(2)不同的下游任务涉及图的不同部分(节点级、边级、图级)需要不同的策略和方法来学习表示。(3)如何设计统一的模型来实现跨领域和in-context learning是不确定的。
OFA (One-for-All)
将不同Domian的图转化为统一的TAG形式
用human-interpretable language来描述节点和边的属性,从而使LLM可以将这些text attribute编码到同一个空间。具体来说,通过以下方式来生成每个节点的text feature:

将不同domain的graph的节点属性用统一形式的文本来描述,如上图中,对于一个节点的特征,它的文本描述以Feature node开头,后面的每个$<\text{feature describe}>:<\text{feature content}>$是该节点的一个type-content文本对。如对于一个molecule graph,其中的一个节点是原子,那么它的type是Atom,它的content是该原子的属性文本描述Carbon, Atomic number 6, helix chirality。同理,边的text feature以Feature edge开头进行文本描述。
在用以上方式得到节点$v_i$的text feature $s_{v_i}$和边$e_{ij}$的text feature $s_{e_{ij}}$后,用LLM(这里用sentence transformer)来将每个节点和边的text feature编码为vector embeddings: $$ x_i = \operatorname{LLM}(s_{v_i}), \quad x_{ij} = \operatorname{LLM}(s_{e_{ij}}) $$
用Nodes-of-Interest (NOI)来统一不同的图任务
图上的任务主要分为3中:node-level tasks,link-level tasks和graph-level tasks。如果要用一个模型来处理这些任务的话,需要将这些任务统一为一个任务以便于在图数据上训练。
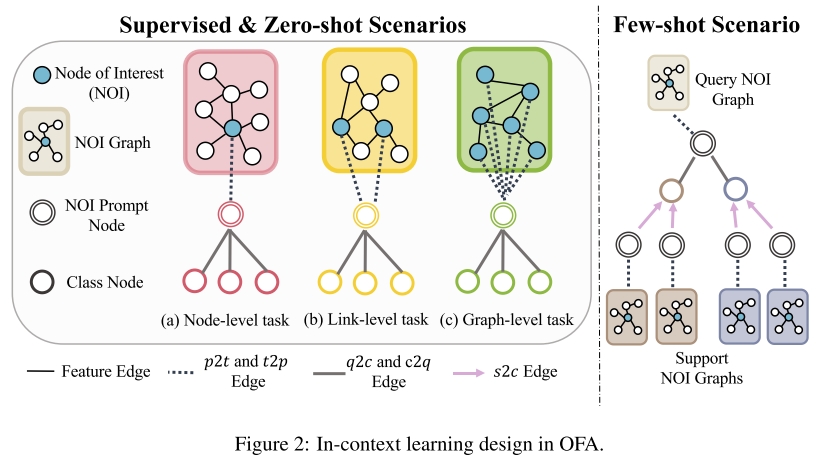
Nodes-of-Interest (NOI)指的是一个任务的目标节点,如上图的蓝色节点所示,表示为$\mathcal{T}$。对于节点级任务,NOI是待预测节点集合,边级任务NOI是待预测是否有边的节点对,图级任务NOI是待预测图中的所有节点。若一个NOI节点$v$的$h$-hop局部子图表示为$\mathcal{S}_h(v)$,那么NOI中所有目标节点的局部子图共同构成了一个NOI subgraph,表示为$\mathcal{G}_h (\mathcal{T})$。 $$ \mathcal{G}_h(\mathcal{T})=\bigcup_{v \in \mathcal{T}} \mathcal{S}_h(v)=\left\{\bigcup_{v \in \mathcal{T}} \mathcal{V}_v^h, \bigcup_{v \in \mathcal{T}} \mathcal{E}_v^h, \bigcup_{v \in \mathcal{T}} \mathcal{R}_v^h\right\} \quad \text{NOI中所有节点的局部子图共同构成} $$ NOI prompt node:定义NOI prompt node,该节点的文本信息用来描述任务,比如某个数据集上的节点分类、图分类等。NOI prompt node的节点text feature以如下形式构建:

即每个数据集的一个task对应于一个prompt node,该node用来描述task。这样,把不同的图任务都用节点的text feature这种统一的形式来表达。
Graph In-Context Learning的图提示范式(Graph Prompting Paradigm)
LLM的一大特性就是它可以通过prompt来实现in-context learning,使得模型可以在不用fine-tuning的情况下适应于不同的任务。比如在few-shot场景下,目标是基于一篇paper的摘要和内容预测它的类别,我们可以为LLM提供每个类别的$k$篇papers作为context加入prompt中,来指导模型基于这些提供的context来生成目标摘要和内容的类别预测。(通过一些任务相关的其他信息来指导模型对目标样本的预测)
本文发现实现图上in-context learning的核心在于操作输入图使其和下游任务对齐。Graph Prompting Paradigm (GPP) 即图提示范式旨在操作输入图使其可以从输入数据本身获得任务相关的信息。如图2中的虚线所示,用来描述任务的NOI prompt node与所有NOI node建立连接(任务的目标节点),表示在这些NOI nodes上执行对应prompt的任务(如节点分类,链路预测,图分类等)。图中的$p2t$和$t2p$ edge表示NOI节点和prompt node之间的边。下一步建立NOI prompt node和具体类别之间的联系,如图2中的Class Node用来描述该分类任务的每个类别的类信息,任务有多少个类,就有多少个Class Node。Class Node的Text feature如下图所示:

Zero-shot Learning: 对于NOI中的一个节点$q$,用于描述它的任务的NOI prompt node $p_q$,以及Class Node $\{c_i | i \in [N]\}$ ,其中$N$为任务的类别数。prompt node,class node,以及和prompt node 连接的所有边(包括与NOI连接的边)共同构成了prompt graph $\mathcal{P}=\left(\mathcal{V}_p, \mathcal{E}_p, \mathcal{R}_p\right)$。
然后,prompt graph $\mathcal{P}=\left(\mathcal{V}_p, \mathcal{E}_p, \mathcal{R}_p\right)$和NOI subgraph (即NOI节点的局部子图)相结合为通用graph model的输入图$\mathcal{G}_m=\left(\mathcal{V}_q^h \cup \mathcal{V}_p, \mathcal{E}_q^h \cup \mathcal{E}_p, \mathcal{R}_q^h \cup \mathcal{R}_p\right)$。如图2中的(a)(b)(c)都是graph model的输入图。通过模型的学习,可以得到每个Class node 的embeddings,如类别$c_i$的Class node embedding为$h_{c_i}$。因为$c_i$与任务相关的prompt node 连接,而prompt node与目标NOI node 连接,因此可以用$h_{c_i}$来推断NOI node属于类别$c_i$的概率: $$ P[\text { NOI belongs to class } i]=\sigma\left(\operatorname{MLP}\left(h_{c_i}\right)\right) $$
4. Talk like a Graph: Encoding Graphs for Large Language Models
prompt engineering的目的是找到一个合适的方式使LLM $f$可以解析问题$Q$,并且得到他的Answer $\mathcal{A}$,即$\mathcal{A} = f(Q)$。本工作的目标是为LLM$f$提供图$G$,使得LLM可以对图做推理QA,即$\mathcal{A} = f(G,Q)$。在该工作中,固定LLM $f$的参数不变,并引入一个图编码函数(graph encoding function)$g(G): G \to W$用于将图结构数据编码成text,以及一个问题重解析函数$q(Q): W \to W$。训练数据$D$有图$G$,问题$Q$和回答$S$组成,即每个训练数据$(G,Q,S) \in D$。训练目标是固定大语言模型$f$不变,找到最佳的图编码函数$g$和问题重解析函数$q$,使得给定训练$G$和$Q$,得到回答$S$的分数最高: $$ \max _{g, q} \mathbb{E}_{G, Q, S \in D} \operatorname{score}_f(g(G), q(Q), S) $$
Graph encoding function $g(G)$
$g(G)$用于将$G$映射为LLM可以处理的token:首先,encode图中的节点,然后encode图中的边。具体编码技术如下图所示:
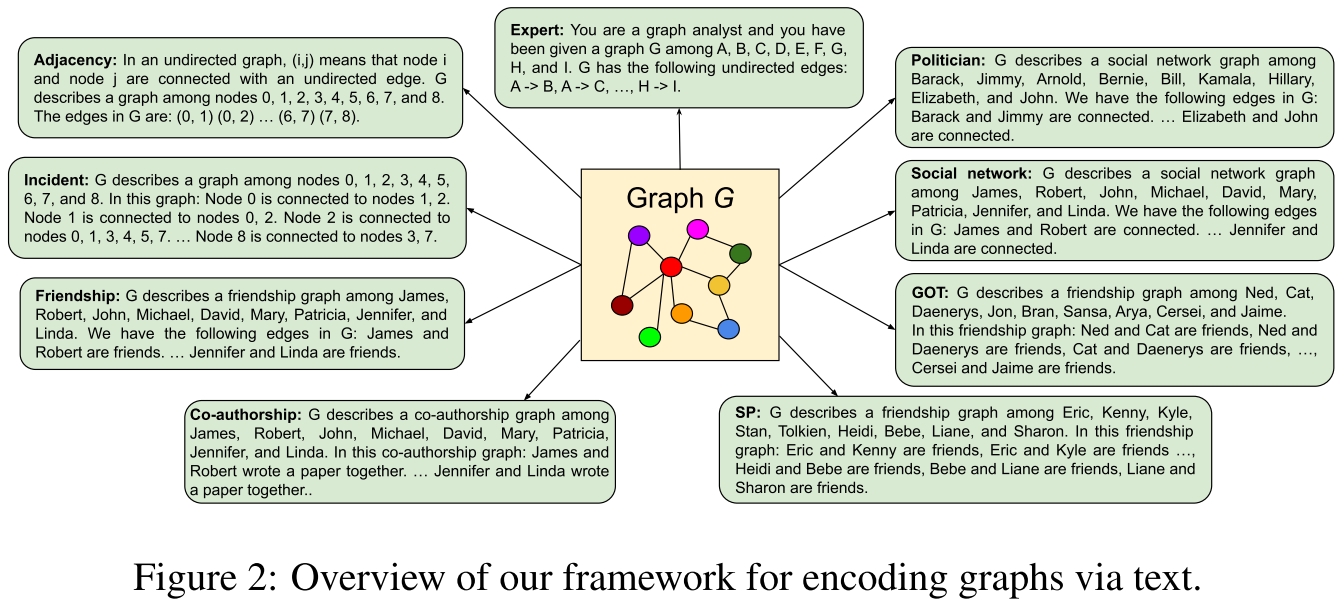
Encoding Nodes:
整型节点编码:$G$ describes a graph among nodes 0,1,2,3,4,5,6,7
使用well-known English first names:$G$ describes a friendship among James, Robert, Michael, Mary.
使用电视剧《权力的游戏》和《南方公园》中流行的角色名字。
包括美国政治家的名字。
用字母表示的。
Representing Edges:
- 用括号表示边:The edge in $G$ given as (0,1), (0,2), …, (6,7), (7,8)
- Friendship: source node and target node are friends. 如 We have the following edges in $G$: James and Robert are friends, … Jennifer and Linda are friends。对应于上面的well-known English first name表示节点
- Coauthorship: 比如 James and Robert wrote a paper together 来表示一条边
- Social network: James and Robert are connected来表示一条边
- Arrows: A->B 来表示边
- Incident: Node 8 is connected to nodes 3,7 来表示每个节点的邻域。
Experiments
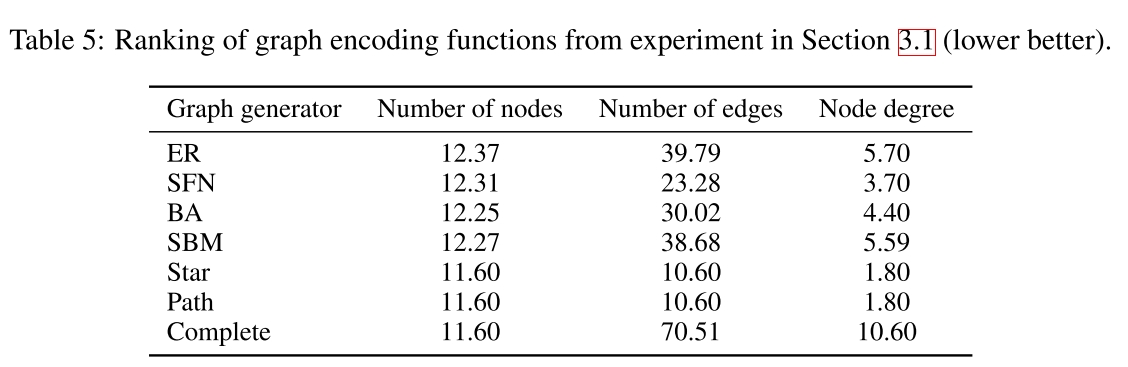
使用PaLM 62B作为LLM,在不同图任务以及不同图编码器下的准确率比较,最有效的prompt (zero-shot、zero-cot、few-show、cot、cot-bag)用下划线标出,最佳图编码器用加粗标出。实验使用ER Graph作为数据集,ER Graph的统计数据如下表所示,可以看出平均节点数为12.37,平均边数为39.79,平均度为5.70。对于边存在任务,有53.96%的情况不存在边,对于cycle check任务,有81.96%的情况存在cycle(因为ER graph很可能存在cycle)。
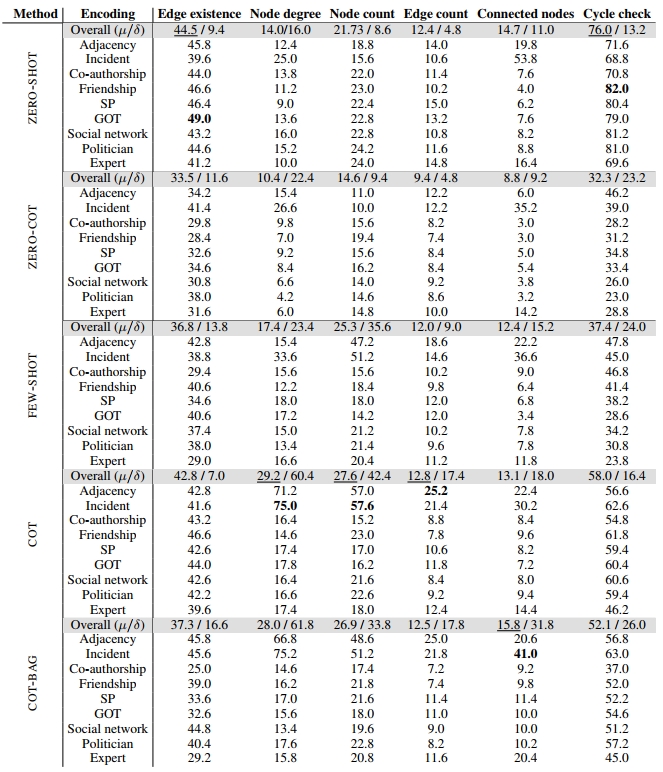
从下面的实验结果可以看出,LLM在所有prompt heuristic的所有graph encoding function上预测的最高边存在概率为44.5%,76%的情况存在cycle。而在Node degree 任务上,均与真实平均度5.7差距较大,平均边数也与真实情况差距较大。
简单的Prompt比如zero-shot 在简单的任务上比复杂的prompt比如zero-cot效果更好,因为简单的任务无需多跳推理。
graph encoding function对LLM影响巨大。
整型节点编码可以提升算数性能,比如node degree、node count和edge count的预测。
5. Can Language Models Solve Graph Problems in Natural Language?
[1] Learning on Large-scale Text-attributed Graphs via Variational Inference.
[2] https://medium.com/@francescofranco_39234/in-context-learning-icl-a775cd8b7261