GNN中的层次叠加需要稀疏矩阵乘法计算带来较大的计算开销,而MLP仅使用node feature可以避免此问题。本文发现大多数message-passing通过将训练参数设置为相同shape,可以推导出等效的MLP(PeerMLP),而使用PeerMLP来作为GNN的初始化参数可以相较于仅使用PeerMLP,效果提升极大。
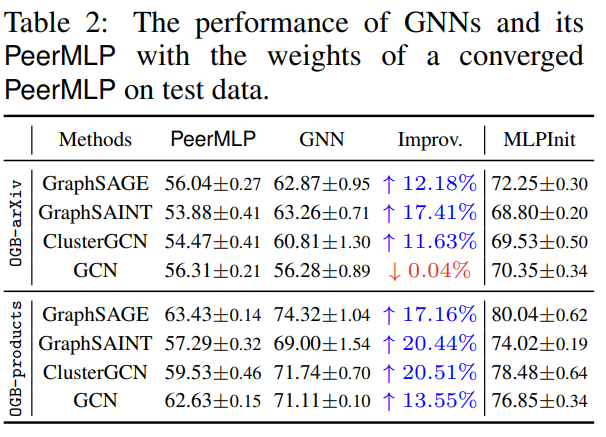
从上图的蓝线可以看出,GNN通常需要更多的训练迭代次数才可以达到收敛,因为其中涉及复杂的稀疏矩阵乘法计算。而MLP不使用结构信息,训练速度更快,因此本文发现MLP和GNN可以有相同的训练权重空间,因此 Can we train GNNs more efficiently by leveraging the weights ofconverged MLPs? 本文进一步发现,对于一个GNN和它对应的PeerMLP (相同的weight),在PeerMLP上训练的权重可以优化GNN。基于该发现,图上训练好的PeerMLP作为GNN的权重矩阵$W$, 然后再考虑结构信息,可以发现GNN的效果相较于PeerMLP有很大的提升。 如表2所示,其中PeerMLP和GNN有相同的权重空间,首先在图上训练PeerMLP,得到收敛时的最有参数$w^\star_{mlp}$,PeerMLP的预测结果为$f_{m l p}\left(\mathbf{X} ; w_{m l p}^\star\right)$, 然后直接使用不训练而直接使用$w_{m l p}^\star$作为GNN的参数,即$f_{g n n}\left(\mathbf{X}, \mathbf{A} ; w_{m l p}^\star\right)$,可以看出,在考虑图结构后,GNN即使不训练,直接使用PeerMLP的权重矩阵,效果也有巨大提升。
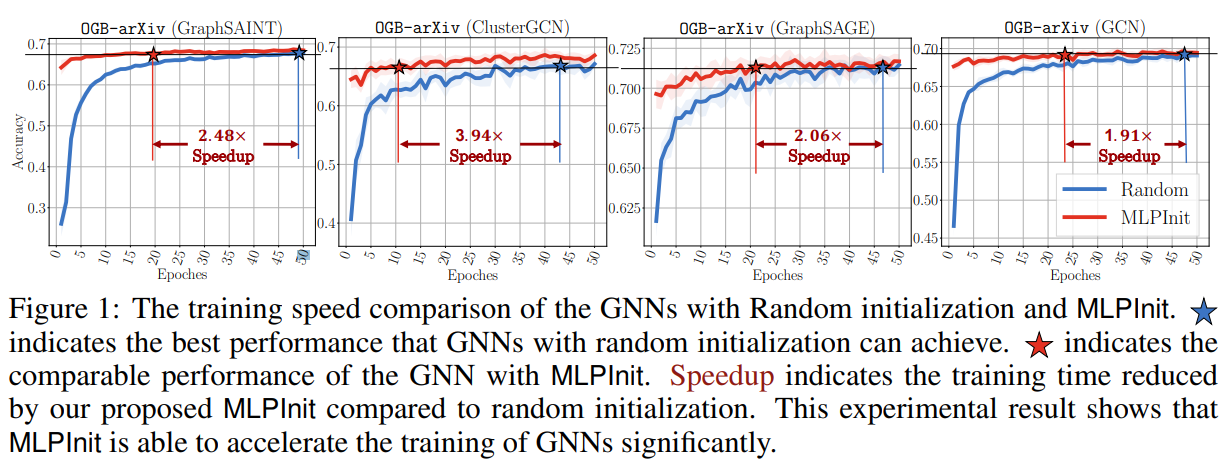
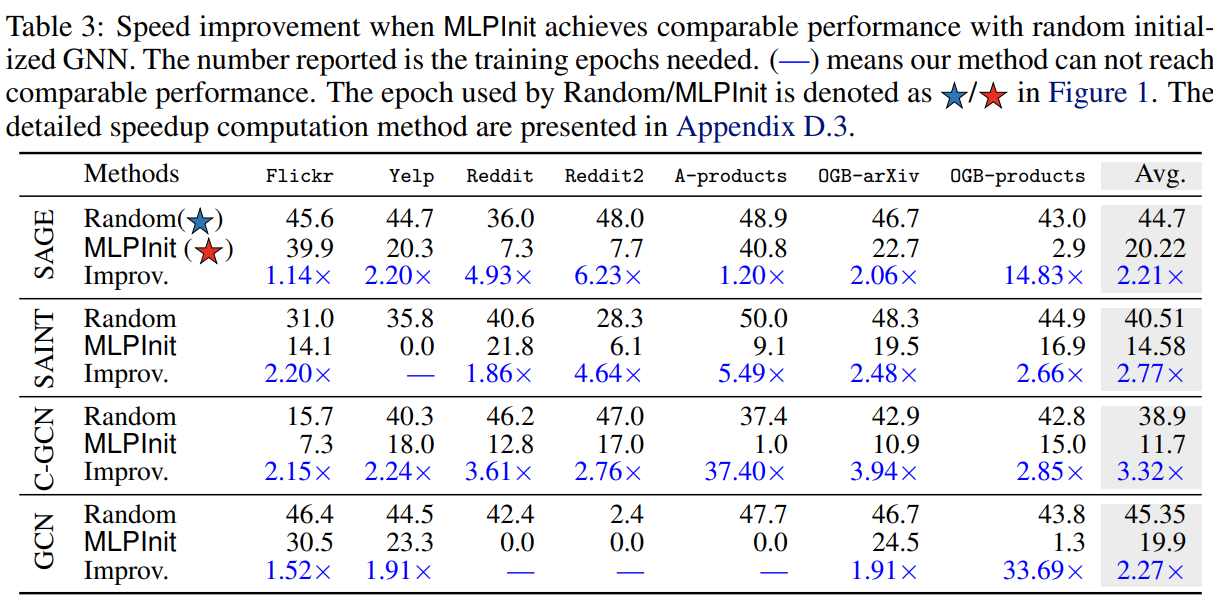
受此启发,本文提出了用收敛的PeerMLP最优权重矩阵,作为GNN的初始化权重。从图1的红线可以看出,相较于随机初始化的GNN,MLPInit初始化的GNN在更少的epoch到达收敛 并且可以达到和相似的准确率。
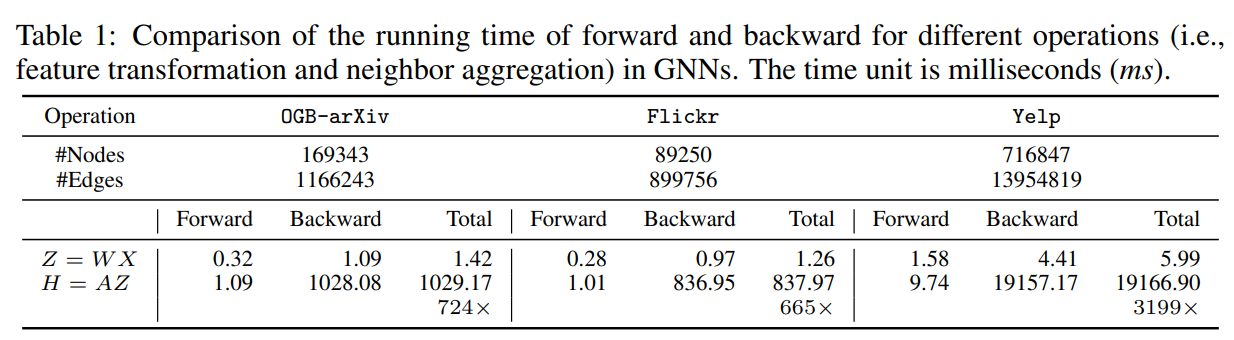
从上表可以看出GNN的Propagation操作$AZ$的前向计算和反向梯度传播的耗时都远远超过Feature Transformation操作$WX$。Feature Tran的操作相对与Propagation,计算成本几乎可以忽略不计,所以如果预训练操作得到的$W$可以使得训练GNN时的epoch大幅下降,可以使模型更加高效。如下表所示,训练PeerMLP的时间再加上的权重迁移到GNN后的fine-tuning时间, 远少于在GNN上直接训练随机初始化参数的时间。
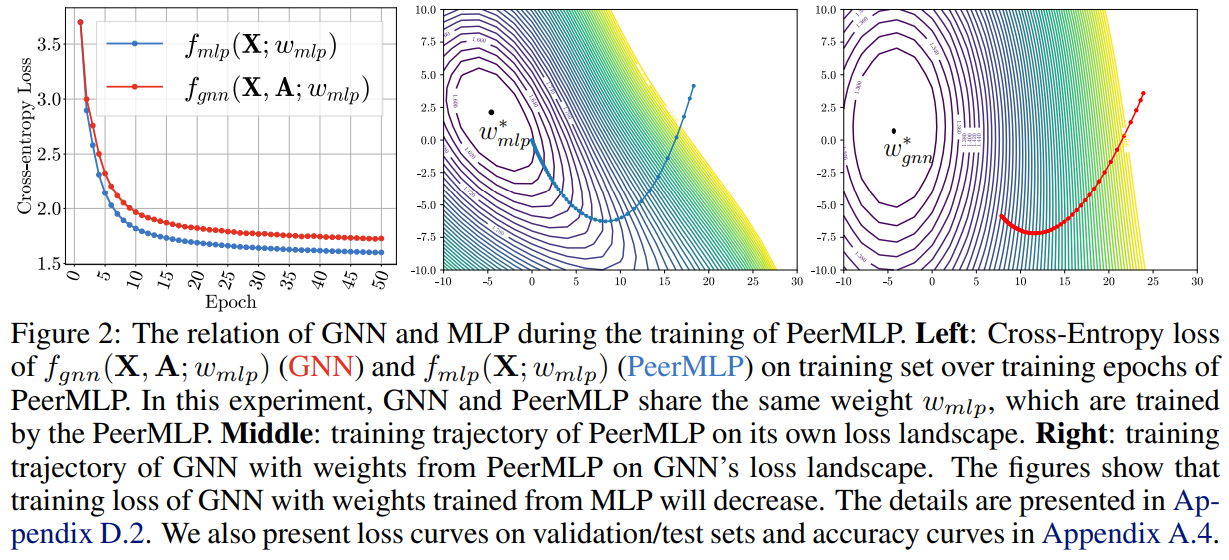
从下图同样可以看出PeerMLP的参数$w_{mlp}$的训练趋势,PeerMLP训练过程中每个epoch的$w_{mlp}$直接迁移到GNN上计算CE损失,可以发现使得MLP 的CE Loss下降的$w_{mlp}$同样可以使得GNN以同样的趋势下降。