最近想好好学一学Deep Learning中的优化算法(不能一直Adam了),看了一些文献,用这篇文章做个总结笔记。
Gradient Desent(梯度下降)
目标函数$f(x)$,其中$x$为模型的待优化参数,对于每个epoch $t$, $\eta_t$表示第$t$个epoch的步长。$x_t$第$t$个epoch时的参数。
(1).梯度下降的原理:目标函数(损失函数)$f(x)$关于参数$x$的梯度是损失函数上升最快的方向。所以只要让$x$沿梯度的反方向走,就可以缩小目标函数。
(2).目标函数关于参数$x$在epoch $t$时的梯度:
$$g_t = \nabla_x f(x_t)$$
(3).我们要最小化$f(x)$, 所以参数$x$需要往梯度的反方向移动:
$$x_{t+1} = x_t-\eta_t g_t$$
其中$x_{t+1}$为$t+1$时刻的参数值。
Stochastic Gradient Desent(随机梯度下降)
梯度下降存在的问题有鞍点问题以及无法找到全局最优解的问题。所以引入SGD。
首先给出无偏估计的定义,稍后会用到:
无偏估计:估计量的均值等于真实值,即具体每一次估计值可能大于真实值,也可能小于真实值,而不能总是大于或小于真实值(这就产生了系统误差)。
深度学习中,目标函数通常是训练集中各个样本损失的平均,假设一个batch的大小为$n$,那么训练这个batch的损失就是$f_{batch}(x) = \frac{\displaystyle\sum_{i=1}^{n} f_i(x)}{n}$ , 所以目标函数对$x$的梯度就是:
$$\nabla f_{batch}(x) = \frac{1}{n} \displaystyle\sum_{i=1}^n \nabla f_i(x)$$
如果使用GD来优化:
$$x_{t+1} = x_{t}- \eta_t \frac{1}{n} \displaystyle\sum_{i=1}^n \nabla f_i(x) \ = x_t-\eta_t \nabla f_{batch}(x)$$
上式可以看出,当训练样本非常大时,n也将边的非常大,那么梯度计算的计算开销就比较大。
随机梯度下降(SGD)的思想是: 以一个batch为例,这个batch中有n个样本,每个样本$i \in {1, \cdots,n}$, 每次从中随机选取一个样本来更新参数$x$。
$$x_{t+1} = x_{t}-\eta_t \nabla f_i(x)$$
这样就更新了一个batch的参数。 对比上面两个式子可以看出SGD降低了计算复杂度。上面两个式子是等价的,因为随机梯度$\nabla f_i(x)$是对梯度$\nabla f_{batch}(x)$的无偏估计,因为:
$$E_i \nabla f_i(\boldsymbol{x}) = \frac{1}{n} \sum_{i = 1}^n \nabla f_i(\boldsymbol{x}) = \nabla f_{batch}(\boldsymbol{x})$$
符合无偏估计的定义。
Momentum(动量法)
Exponentially weighted moving averages(EMA)
EMA,指数加权移动平均数。
在GD中,如果学习率过大,会导致目标函数发散,而无法逼近最小值,如下图所示: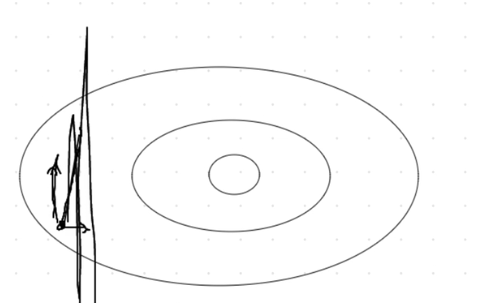
如果学习率很低,那么会缓慢接近最优点,如下图红色轨迹: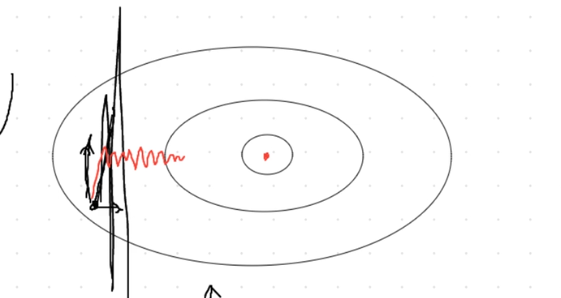
我们希望在学习率较小的时候可以更快逼近最优点,在学习率大的时候自变量可以不发散,即在正确的方向上加速下降并且抑制震荡,也就是达到如下的效果: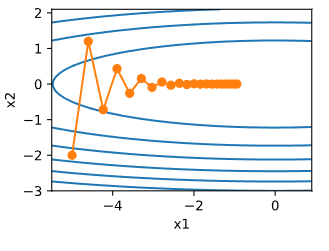
因此引入EMA。给定参数$0 \leq \gamma < 1$,当前时间步$t$的变量$y_t$是上一时间步$t-1$的变量$y_{t-1}$和当前时间步另一变量$x_t$的线性组合。
$$y_t = \gamma y_{t-1} + (1-\gamma) x_t$$
展开上式:
$$\begin{split}\begin{aligned}
y_t &= (1-\gamma) x_t + \gamma y_{t-1}\\
&= (1-\gamma)x_t + (1-\gamma) \cdot \gamma x_{t-1} + \gamma^2y_{t-2}\\
&= (1-\gamma)x_t + (1-\gamma) \cdot \gamma x_{t-1} + (1-\gamma) \cdot \gamma^2x_{t-2} + \gamma^3y_{t-3}\\
&\ldots
\end{aligned}\end{split}$$
上式可以看出当前时刻变量是对过去时刻变量做指数加权,离当前时刻越近,加权越大(越接近1)。
在现实中,我们将$y_t$看作是最近$1/(1-\gamma)$个时间步的$x_t$的加权平均,当$\gamma = 0.95$时,是最近20个时间步的$x_t$值的加权平均。当$\gamma=0.9$时,可以看做是最近10个时间步加权平均。
动量法
$$\begin{split}\begin{aligned}
\boldsymbol{v}_t &= \gamma \boldsymbol{v}_{t-1} + \eta_t \boldsymbol{g}_t, \\
\boldsymbol{x}_t &= \boldsymbol{x}_{t-1} - \boldsymbol{v}_t,
\end{aligned}\end{split}$$
其中$g_t = \nabla f_i(x)$上式可以看出,如果$\gamma=0$,则上式就是一个普通的随机梯度下降法。$0 \leq \gamma < 1$. $\gamma$一般取0.9。
一般,初始化$v_0=0$, 则
$$v_1=\eta_t g_t \\ v_2=\gamma v_1+\eta_t g_t = \eta_t g_t(\gamma+1) \\ v_3 = \eta_t g_t (\gamma^2+\gamma+1) \\ v_{inf} = \frac{(\eta_t g_t)\cdot(1-\gamma^{inf+1})}{1-\gamma}\approx \frac{(\eta_t g_t)}{1-\gamma}$$
相比原始梯度下降算法,动量梯度下降算法有助于加速收敛。当梯度与动量方向一致时,动量项会增加,而相反时,动量项减少,因此动量梯度下降算法可以减少训练的震荡过程。
换种方式理解动量法:
如上图所示,A点为起始点,首先计算A点的梯度$\nabla a$,下降到B点,
$$\theta_{new} = \theta-\eta\nabla a$$
其中$\theta$为参数, $\eta$为学习率
到达B点后要加上A点的梯度,但是A点的梯度有个衰减值$\gamma$,推荐取0.9,相当于加上一个来自A点递减的加速度。这样的做法可以让早期的梯度对当前梯度的影响越来越小,如果没有衰减值,模型往往会震荡难以收敛,甚至发散。所以B点的参数更新公式是这样的:
$$v_t = \gamma v_{t-1}+\eta \nabla b$$
$$\theta_{new} = \theta-v_t$$
其中$v_{t-1}$表示之前所有步骤累计的动量和,$\nabla b$为B点的梯度方向。这样一步一步下去,带着初速度的小球就会极速的奔向谷底。
AdaGrad
假设目标函数有两个参数分别为$x_1$,$x_2$,若梯度下降迭代过程中,始终使用相同的学习率$\eta$:
$$x_{1_{new}} = x_1-\eta \frac{\partial f}{\partial x_1}$$
$$x_{2_{new}} = x_2-\eta \frac{\partial f}{\partial x_2}$$
AdaGard算法根据自变量在每个维度的梯度值来调整各个维度上的学习率,避免学习率难以适应维度的问题。adagrad方法是将每一个参数的每一次迭代的梯度取平方累加再开方,用基础学习率除以这个数,来做学习率的动态更新。
$\nabla_{\theta_i} J(\theta)$表示第$i$个参数的梯度,其中$\theta=(\theta_1,\theta_2,…)$有$n$个参数。如果使用SGD来优化第$i$个参数,我们可以表示为:
$$\theta_{i_new} = \theta_i-\eta \nabla_{\theta_i}J(\theta)$$
如果使用Adagrad,则可以表示为这样:
$$\theta_{i,t+1}=\theta_{i,t}-\frac{\eta}{\sqrt{G_{i,t}+\epsilon}} \nabla_{\theta_{i,t}}J(\theta)$$
$i,t$ 表示优化参数$\theta_i$时的第$t$次迭代,$\epsilon$防止分母为0,可以取$10^{-6}$,$G_{i,t}$表示对参数$\theta_i$优化的前$t$步的梯度的累加:
$$G_{i,t} = G_{i,t-1}+\nabla_{\theta_{i,t}}J(\theta) $$
新公式可以简化成:
$$\theta_{t+1}= \theta_t-\frac{\eta}{\sqrt{G_t+\epsilon}}\nabla_{\theta_t}J(\theta)$$
可以从上式看出,随着迭代的推移,新的学习率$\frac{\eta}{\sqrt{G_t+\epsilon}}$在缩小,说明Adagrad一开始激励收敛,到了训练的后期惩罚收敛,收敛速度变慢
RMSprop
主要解决Adagrad学习率过快衰减问题,类似动量的思想,引入一个超参数,在积累梯度平方项进行衰减.
$$s = \gamma \cdot s +(1-\gamma) \cdot \nabla J(\theta) \odot \nabla J(\theta) $$
参数$\theta$的迭代目标函数可以改写为:
$$\theta_{new} = \theta - \frac{\eta}{\sqrt{s+\varepsilon}} \odot \nabla J(\theta)$$
可以看出$s$是梯度的平方的指数加权移动平均值,$\gamma$一般取0.9,有助于解决 Adagrad中学习率下降过快的情况。
Adaptive moment estimation(Adam)
Adam可以说是用的最多的优化算法,Adam通过计算一阶矩估计和二阶矩估计为不同的参数设计独立的自适应学习率。
Adabound
正在学习中
参考文献:
https://zhuanlan.zhihu.com/p/32626442
https://zhuanlan.zhihu.com/p/31630368
https://zh.gluon.ai/
https://blog.csdn.net/tsyccnh/article/details/76270707